Basierend auf diesem Blogpost habe ich mir eine Lösung für die AVM-DECT-Steckdosen FRITZ!Dect 200 gebastelt. Das ganze war als reine Fingerübung gedacht, da es aber immer wieder Nachfragen gibt, hier Details zur Umsetzung.
Das ganze läuft auf einem Uberspace als Webserver. Nehmen wir mal an, der Uberspace-Name ist jarvis und läuft auf dem Server stark. Dieser Webspace ist dann über https://jarvis.stark.uberspace.de/ erreichbar. Wichtig: jarvis immer durch den Namen eures Uberspaces ersetzen (vergebt ihr beim Anlegen) und stark immer durch den Namen des Servers, auf dem euer Uberspace liegt (bekommt ihr nach dem Anlegen automatisch zugewiesen und ist auf dem Reiter ‘Datenblatt’ ersichtlich).
Wir verbinden uns per ssh und wechseln in das DocumentRoot, klonen dort das git-Repo und benennen den Ordner in was brauchbares um:
cd /var/www/virtual/jarvis/ git clone https://github.com/gaiterjones/amazon-alexa-php-hello-world-example mv amazon-alexa-php-hello-world-example/ alexa |
Als nächstes müssen wir mittels Symlink dafür sorgen, dass der Webserver ein anderes Verzeichnis als DocumentRoot benutzt:
ln -s alexa/PAJ/www/Amazon/ jarvis.stark.uberspace.de |
Abschließend brauchen wir noch die Datei, die mit der AVM-AHA-Interface spricht. Ich hab da schon mal was vorbereitet. Diese kommt in das folgende Verzeichnis:
/var/www/virtual/jarvis/alexa/PAJ/Application/Amazon/Alexa/Intent |
Damit das funktioniert muss in Zeile 25 der Host geändert werden unter dem die FRITZ!Box aus dem Internet erreichbar ist. Außerdem ist den Zeilem 239 und 240 Benutzername und Passwort. Es ist zwingend notwendig, dass für die Anmeldung an der FRITZ!Box sowohl Benutzername als auch Passwort benötigt werden. Wenn das noch nicht der Fall ist muss man das entsprechend umstellen.
Auf jeden Fall sollte ein eigener User für die Kommunikation mit Alexa angelegt werden!
Jetzt loggen wir uns auf developer.amazon.com mit unserem Amazon-Developer-Account ein. Wer noch keinen hat registriert sich schnell einen, es muss sich dabei um den gleichen Account handeln der auch für Alexa hinterlegt ist, sonst steht der Skill anschließend nicht zur Verfügung.
Der Skill basiert auf dem Custom Interaction Model, deshalb ist auch ein Codewort erforderlich. Wenn man direkt die Smart Home Skill API verwendet benötigt man das nicht, damit habe ich mich aber nicht beschäftigt, da man dafür zwingend alles als AWS Lambda ARN hosten muss. Damit kann sich gerne AVM auseinandersetzen.
Unser Skill hat den Invocation Name ‘fritzbox’, das Intent Schema sieht so aus:
{
"intents": [
{
"intent": "FritzBox",
"slots": [
{
"name": "trigger",
"type": "TRIGGER"
},
{
"name": "state",
"type": "STATE"
},
{
"name": "action",
"type": "ACTION"
},
{
"name": "device",
"type": "DEVICE"
}
]
}
]
} |
Die Slots so:
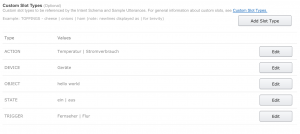
Und die Sample Utterances so:
FritzBox schalte {trigger} {state}
FritzBox liste meine {device} auf
FritzBox ich brauche die Liste der {device}
FritzBox ich brauche die {device} Liste
FritzBox wie ist die {action} von {trigger}
FritzBox nach dem {action} von {trigger}
FritzBox nach den {action} zu {trigger} |
Wichtig ist beim SSL-Zertifikat die Option ‘My development endpoint is a sub-domain of a domain that has a wildcard certificate from a certificate authority’ zu wählen, sonst läuft es nicht.
Im Testbereich können wir jetzt beliebige Test durchführen, z.B. ‘sag fritzbox schalte Bad ein’. Die Antwort sollte in etwa so aussehen:
{
"version": "1.0",
"response": {
"outputSpeech": {
"type": "PlainText",
"text": "Bad wurde eingeschaltet"
},
"card": {
"text": "Bad wurde eingeschaltet",
"title": "FRITZ!Box",
"image": {
"smallImageUrl": "https://jarvis.stark.uberspace.de/alexaCardImage.php?size=small&image=default",
"largeImageUrl": "https://jarvis.stark.uberspace.de/alexaCardImage.php?size=large&image=default"
},
"type": "Standard"
},
"shouldEndSession": true
},
"sessionAttributes": {}
} |
Und damit sollten sich die Steckdosen entsprechend schalten und abfragen lassen. Prinzipiell müsste das auch mit Thermostaten funktionieren, ich hab aber keine und kann das daher nicht testen oder implementieren.
